哈希表
哈希表与哈希函数
哈希表通过建立 key 和 value 之间的映射,实现高效的元素查询。我们可以使用数组来实现哈希表。在哈希表中,可以将数组中的每个空位称为 “桶”,每个桶可以存储一个键值对。因此,查询操作就是找到 key 对应的桶,并在桶中获取 value。基于 key 定位对应的桶,需要通过哈希函数来实现。

哈希函数能将一个较大的输入空间映射到一个较小的输出空间。换句话说,输入一个 key,可以通过哈希函数得到该 key 对应的键值对在数组中的存储位置。
假设哈希表容量为 capacity = 100,输入桶的 key 并通过哈希算法计算得到哈希值,将哈希值对桶的数量 capacity 进行取模运算,从而获取该 key 对应的索引值 index。然后,我们就可以通过 index 在哈希表中访问对应的桶,从而获取 value。
index = hash(key) % capacity
哈希冲突
即使哈希函数的输入空间远远大于输出空间,但是也会存在多个输入对应相同输出的情况。如图所示,20336 和 12836 输入哈希函数的结果都指向同一个桶,我们将这种情况称为 “哈希冲突”。
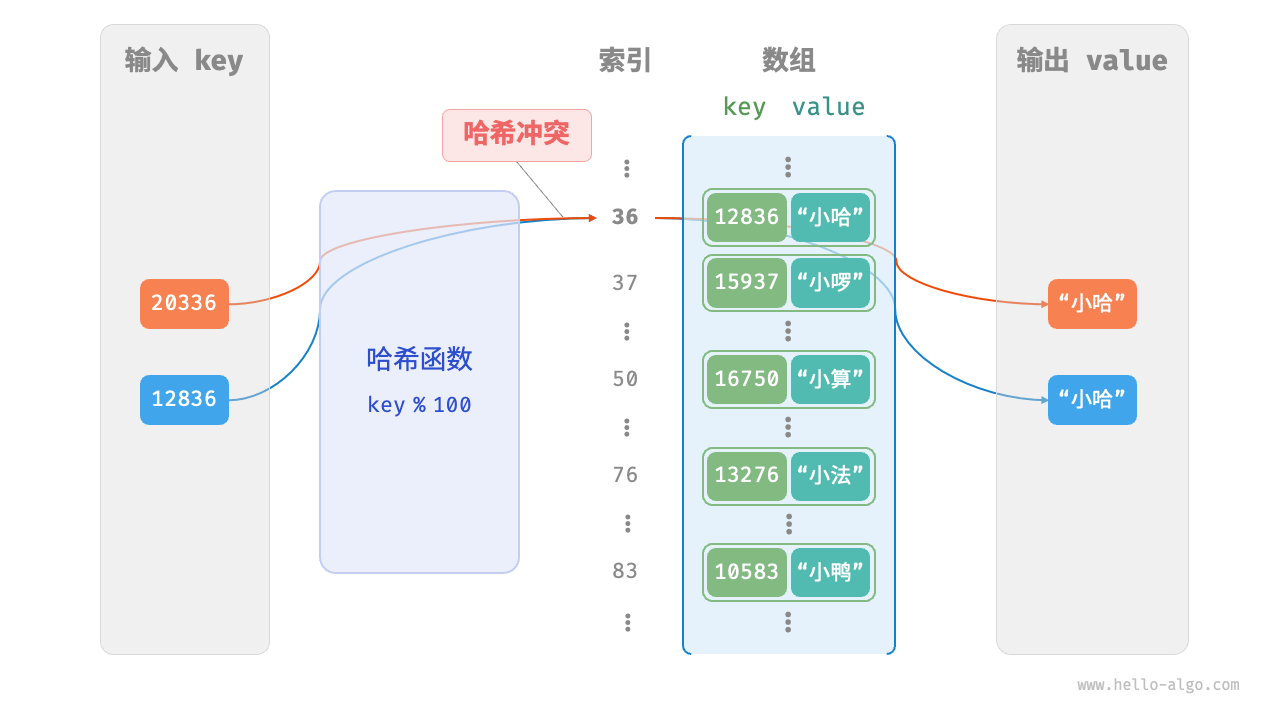
12836 % 100 = 36
20336 % 100 = 36
哈希表扩容
如果哈希表容量越大,多个 key 被分配到同一个桶的概率就越低,冲突就越少。所以我们可以通过扩容哈希表来减少哈希冲突。

但是这种方式效率太低,因为哈希表扩容需将所有键值对从原哈希表迁移至新哈希表,非常耗时;并且由于哈希表容量 capacity 改变,我们需要通过哈希函数重新计算所有键值对的存储位置,这进一步增加了扩容过程的计算开销。为了提升效率,我们一般使用 “链式地址” 和 “开放寻址” 这两种方法优化哈希表。
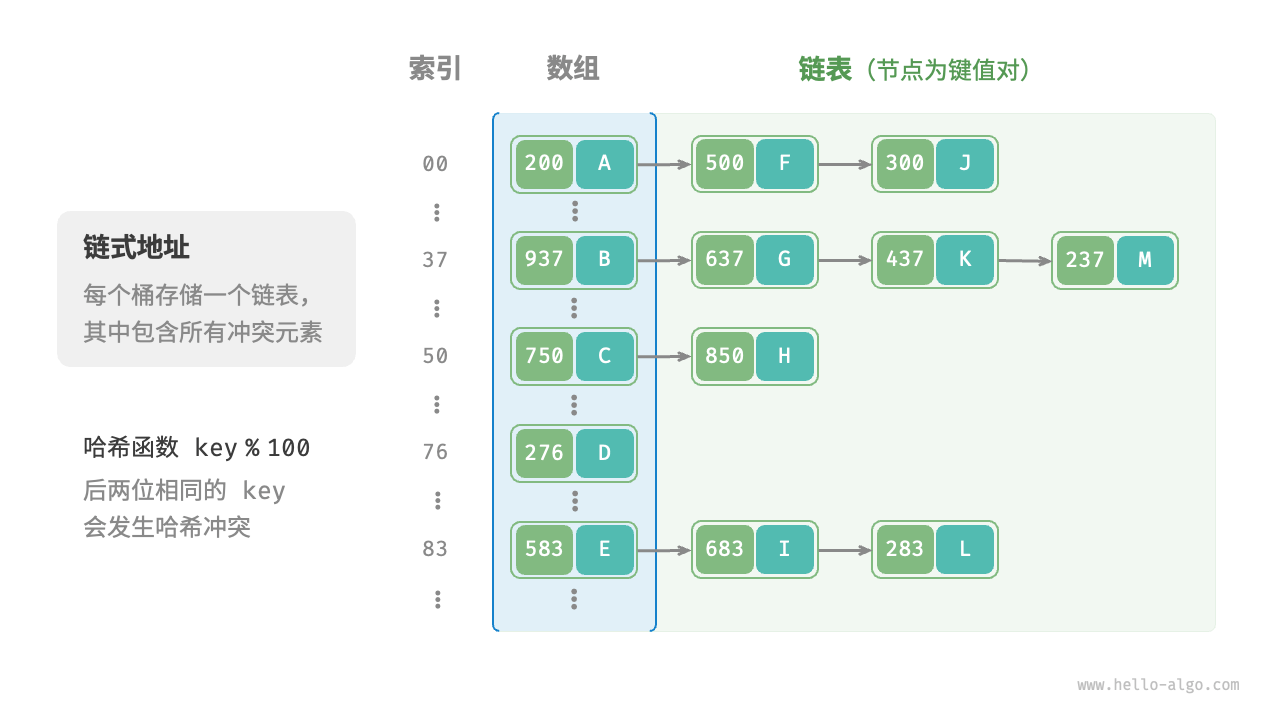
链式地址
在原始哈希表中,每个桶仅能存储一个键值对。链式地址将每个元素转换为链表(或数组),将键值对作为链表节点,将所有发生冲突的键值对都存储在同一链表中。并且,将产生新冲突的元素插入头节点的效率更高。
输入 key ,经过哈希函数得到桶的索引,就可以访问链表头节点,接下来就是通过链表操作去查找目标元素。
开放寻址
开放寻址不引入额外的数据结构,而是通过“多次探测”来处理哈希冲突,探测方式主要包括线性探测、平方探测和多次哈希。
线性探测
线性探测采用固定步长(通常为 1)的线性搜索来进行探测。插入元素时,通过哈希函数计算桶索引,若发现桶内已有元素,则从冲突位置向后线性遍历,直至找到空桶,将元素插入其中。查找元素时,若发现哈希冲突,则使用相同步长向后进行线性遍历,直到找到目标元素;如果遇到空桶,说明目标元素不在哈希表中 。

在进行删除操作时,如果将元素直接从哈希表中移除(赋值为 null),这会导致在哈希表中产生一个空桶。再次查找元素时,线性探测到这个空桶就会返回,如果目标元素在该空桶之后,就会导致误判了该元素不存在。

为了解决这个问题,我们可以采用懒删除机制:用一个常量来标记这个桶,而不是直接从哈希表中移除元素。当线性探测到被标记的桶时,不会把它当作一个空桶,而是会向下继续遍历。
线性探测还有一个问题。如果插入一串连续的元素,例如 “22-23-24-25-26”,那就意味着索引为 “2-3-4-5-6” 的位置都有元素。被连续占用的位置越长,发生哈希冲突的可能性就越大,从而产生 “聚集现象”,这对增删改查操作都会造成影响。
平方探测
平方探测优化了探测时的步长,如果线性探测的步长固定为 1,那么平方探测的步长就是 “1, 4, 9 ...”。这样可以试图缓解线性探测的聚集现象,并且有助于数据分布更加均匀。
但是平方探测依然存在问题,如果插入 “32-112-82-2-192” 这样连续的元素,它们依次累加的时候步长是相同的,这种情况下会造成步长不同的聚集。并且,由于平方的增长,平方探测可能不会探测整个哈希表,这意味着即使哈希表中有空桶,平方探测也可能无法访问到它。
多次哈希
线性探测和平方探测都会出现不同情况(相同步长或不同步长)的聚集现象,多次哈希依然是对步长进行优化。将哈希计算的结果作为步长,如果依然出现冲突,尝试再次哈希,直到找到空位后插入元素。查找元素时,按照相同的哈希顺序进行查找。与线性探测相比,多次哈希不易产生聚集,但多个哈希函数会带来额外的计算量。
负载因子
负载因子表示哈希表的元素数量和哈希表容量的比值,用于衡量哈希冲突的严重程度,也常作为哈希表扩容的触发条件。链式地址的平均探测步长与负载因子的比值呈线性增长;而开放寻址的平均探测步长与负载因子的比值呈指数增长。由此可见,在链式地址中负载因子的增加对平均探测步长的影响更平缓。
哈希算法
链式地址和开放寻址只能保证哈希表可以在发生冲突时正常工作,而无法减少哈希冲突的发生。所以,我们需要设计一种哈希算法去降低哈希冲突的发生概率。一个优秀的哈希算法需要使用霍纳算法并与质数进行运算。
const hash = (key: string, capacity: number) => {
let hashCode = 0
// 霍纳算法
for (let i = 0; i < key.length; i++) {
hashCode = 37 * hashCode + key.charCodeAt(i)
}
// 输出空间 [0, capacity)
return hashCode % capacity
}
然而,这类简单的算法远远没有达到哈希算法的设计目标。在实际中,我们通常会用一些标准哈希算法,例如 MD5、SHA-1、SHA-2 和 SHA-3 等。它们可以将任意长度的输入数据映射到恒定长度的哈希值。
哈希表
真实开发中链式地址的使用情况更多。所以我们使用链式地址来封装一个哈希表。
class Pair<T> {
key: string
val: T
constructor(key: string, val: T) {
this.key = key
this.val = val
}
}
class HashMap<T> {
/**
* 哈希表容量
*/
private capacity = 7
/**
* 所有的桶
*/
private buckets: (Pair<T>[] | null)[]
/**
* 元素数量
*/
private length = 0
constructor(pair?: Pair<T>) {
this.buckets = new Array(this.capacity).fill(null)
if (pair && pair.key && pair.val) {
this.set(pair.key, pair.val)
}
}
/**
* 哈希函数
* @param key - 键
*/
private hash(key: string) {
let hashCode = 0
for (let i = 0; i < key.length; i++) {
hashCode = 37 * hashCode + key.charCodeAt(i)
}
return hashCode % this.capacity
}
/**
* 哈希表的值
*/
get val() {
return this.buckets
}
/**
* 哈希表的元素数量
*/
get size() {
return this.length
}
/**
* 负载因子
*/
private get loadFactor() {
return this.length / this.capacity
}
/**
* 查找元素
* @param key - 键
*/
get(key: string) {
const index = this.hash(key)
const bucket = this.buckets[index]
// 如果桶为 null,说明目标元素不存在
if (!bucket) return null
// 如果桶中存在目标元素,直接返回
for (const pair of bucket) {
if (pair.key === key) return pair
}
// 目标元素不存在
return null
}
/**
* 插入或修改元素
* @param key - 键
* @param val - 值
*/
set(key: string, val: T) {
const index = this.hash(key)
// 如果桶为 null,就初始化为一个空数组
const bucket = this.buckets[index] ?? []
this.buckets[index] = bucket
// 如果存在目标元素,则修改数据
for (const pair of bucket) {
if (pair.key === key) {
pair.val = val
return
}
}
// 没有找到目标元素,则插入数据
bucket.push(new Pair(key, val))
this.length++
// 负载因子 > 0.75,进行扩容
if (this.loadFactor > 0.75) {
this.resize(this.capacity * 2)
}
}
/**
* 删除元素
* @param key - 键
*/
del(key: string) {
const index = this.hash(key)
let bucket = this.buckets[index]
// 如果桶为 null,说明目标元素不存在
if (!bucket) return null
// 如果桶中存在目标元素,直接返回
for (const pair of bucket) {
if (pair.key === key) {
bucket = bucket.filter(item => item.key !== pair.key)
this.buckets[index] = bucket.length ? bucket : null
this.length--
// 负载因子 < 0.75,进行缩容
if (this.loadFactor < 0.25) {
this.resize(Math.floor(this.capacity / 2))
}
return pair
}
}
// 目标元素不存在
return null
}
/**
* 重新计算哈希表容量(扩容/缩容)
*/
private resize(n: number) {
const buckets = this.buckets // 原来的桶
this.capacity = this.nextPrime(n)
this.buckets = new Array(this.capacity).fill(null)
this.length = 0
for (const bucket of buckets) {
if (!bucket) continue
for (const pair of bucket) {
// 将原来所有的键值对重新插入到新的哈希表中
this.set(pair.key, pair.val)
}
}
}
/**
* 判断是否为质数
* @param n - 任意数字
*/
private isPrime(n: number) {
if (n <= 1) return false
for (let i = 2; i * i <= n; i++) {
if (n % i === 0) return false
}
return true
}
/**
* 获取 >= n 的下一个质数
* @param n - 任意数字
*/
private nextPrime(n: number) {
while (true) {
if (this.isPrime(n)) return n
n++
}
}
}